
Онлайн-компаниям часто бывает трудно создать внутреннюю команду, которая бы следила за всеми трендами в области цифрового риск-менеджмента и эффективно применяла их в компании. Особенно сложной эта задача становится в условиях постоянно изменяющихся технологий и рыночных трендов, где необходимо всегда оставаться в курсе последних инноваций и быть готовым к быстрой адаптации.
Для наших клиентов, которые сталкиваются с трудностями при формировании риск-менеджмент команд, мы разработали новый инструмент - JuicyScoreAI, предназначенный для автоматизации процесса построения кастомных анти-фрод скорингов и выбора оптимальных переменных. Он объединяет мощные аналитические возможности в интуитивно понятный пользовательский интерфейс, что делает его доступным как для начинающих пользователей, так и для опытных специалистов по работе с данными.
Что такое JuicyScoreAI?
Основная цель JuicyScoreAI — способствование эффективной разработке и развертыванию моделей машинного обучения. Автоматизируя важные этапы, такие как анализ данных и выбор переменных, JuicyScoreAI помогает финансовым организациям оптимизировать свои усилия по прогностическому моделированию, что дает более точную оценку и приводит к отличным результатам. JuicyScoreAI будет особенно полезен в сценариях, где требуется быстрая итерация и проверка моделей, что позволит пользователям быстро адаптироваться к новым данным или изменяющимся условиям.
По сути, новый продукт содержит в себе онлайн-функционал для автоматизации кастомных антифрод-скорингов на основе инфраструктуры JuicyScore. Он служит для увеличения полезности использования данных JuicyScore в целом, а также будет полезен в случаях, когда сложно создать свою кастомную антифрод-модель на основе имеющейся инфраструктуры онлайн-бизнеса.
Для кого будет полезен JuicyScoreAI?
JuicyScoreAI создан для широкого круга пользователей: от аналитиков данных, которым необходимо выполнить быстрый исследовательский анализ данных, до опытных специалистов по обработке данных, разрабатывающих надежные прогностические модели.
Благодаря интеграции с существующими рабочими процессами обработки данных JuicyScoreAI станет важнейшим инструментом в арсенале любой организации, которая полагается на принятие решений на основе данных. Например, в области финансов, где данные имеют решающее значение, JuicyScoreAI расширяет возможности извлечения значимой информации из сложных наборов данных. Продукт поможет специалистам по рискам найти для себя более простые подходы к построению кастомизированных моделей.
Ключевые возможности JuicyScoreAI:
• Подготовка данных: пользователи могут загружать свои наборы данных непосредственно в личный кабинет. JuicyScoreAI поддерживает несколько форматов данных и гарантирует сохранение целостности данных от загрузки до анализа.
• Анализ данных: инструмент автоматически выполняет статистический анализ предоставленных данных, рассчитывая такие важные показатели, как коэффициент Джини, статистика KS, информационная ценность (IV) и p-значения. Этот анализ помогает пользователям определить наиболее подходящие переменные и понять статистическую значимость данных.
• Разработка моделей: JuicyScoreAI предлагает гибкие возможности разработки моделей, включая обобщенные линейные модели (GLM), деревья решений и градиентный бустинг (данный список постоянно расширяется). Пользователи могут выбрать наиболее подходящий метод моделирования на основе результатов анализа и адаптировать свой подход к конкретным потребностям бизнеса.
Кроме того, с помощью решения JuicyScoreAI пользователи могут выявлять переменные наиболее значимые для роста бизнеса, сравнивать различные AI методы оценки фрод-рисков, привлекать экспертов JuicyScore для дополнительных консультаций по построению кастомной модели.
JuicyScoreAI: как это работает?
Следует отметить, что JuicyScoreAI является комплиментарным продуктом и представляет собой надстройку над уже установленным решением JuicyScore. Эксперт, ответственный за риски в онлайн-бизнесе, загружает данные по флагам: список сессий с выставленными значениями по фроделентности отдельных сессий/заявок. На основании загруженого файла JuicyScoreAI выдает ответ по 10 переменным или так называемым индексам-IDX. Агрегированные переменные IDX представляют собой совокупность редких событий и факторов одной природы, собранных с помощью алгоритмов Deep Machine Learning в единую переменную, которую можно использовать как для моделирования, так и для встраивания в систему принятия решений кредитных организаций.
Важно отметить, что все индексы IDX были созданы как гауссовские переменные. Это было сделано по нескольким причинам: во-первых, к ним применима оценка/проверка статистической значимости (в смысле классического p уровня значимости), во-вторых - они позволяют структурировать все вероятностное пространство в зависимости от типа фрод-событий. Подробнее об индексах можно узнать в нашем материале по оценке риска редких событий. На основании индексов строится ответ по скорингу.
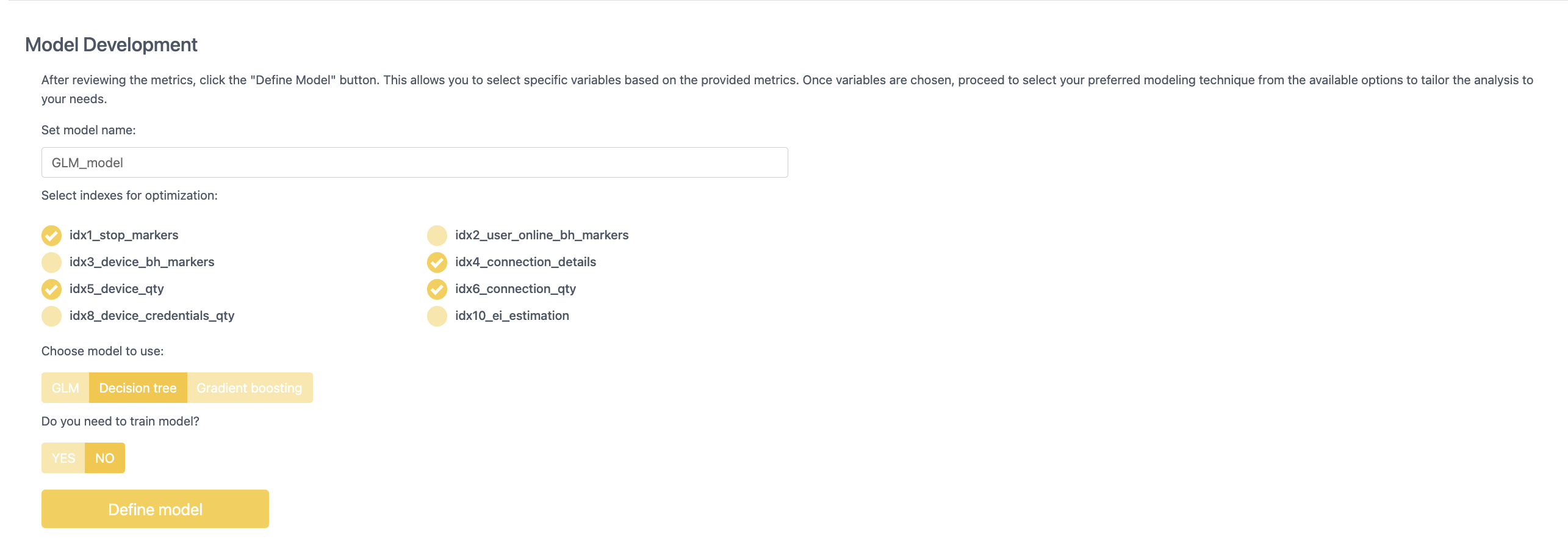
Создание модели: эксперт может выбирать наиболее подходящие индексы для своей модели и выбирать алгоритм машинного обучения, по которому будет строится модель.
На основании 10 индексов мы получаем распределение по предсказательной силе каждого из индексов. Преимущество JuicyScoreAI заключается в том, что это решение работает с данными клиента и обучается на текущих сессиях.
Таким образом мы можем получить плюсы информативности индексов из дженерик-скора (API v15), который представляет ансамбль моделей, построенных на агрегатах IDX1-IDX10 и ряда вспомогательных переменных. За основу берутся данные, собираемые во время работы продуктов JuicyScore или JuicyID, далее на этих данных строится модель, которая не является общей или базовой, но идеально подходит для каждого конкретного бизнес-кейса. Таким образом у эксперта появляется разносторонние инструменты для управления моделями - более базовая и общая модель, которая подходит всем, а также модель, которая основана на данных компании, поэтому скоринг является более точным и аккуратным.
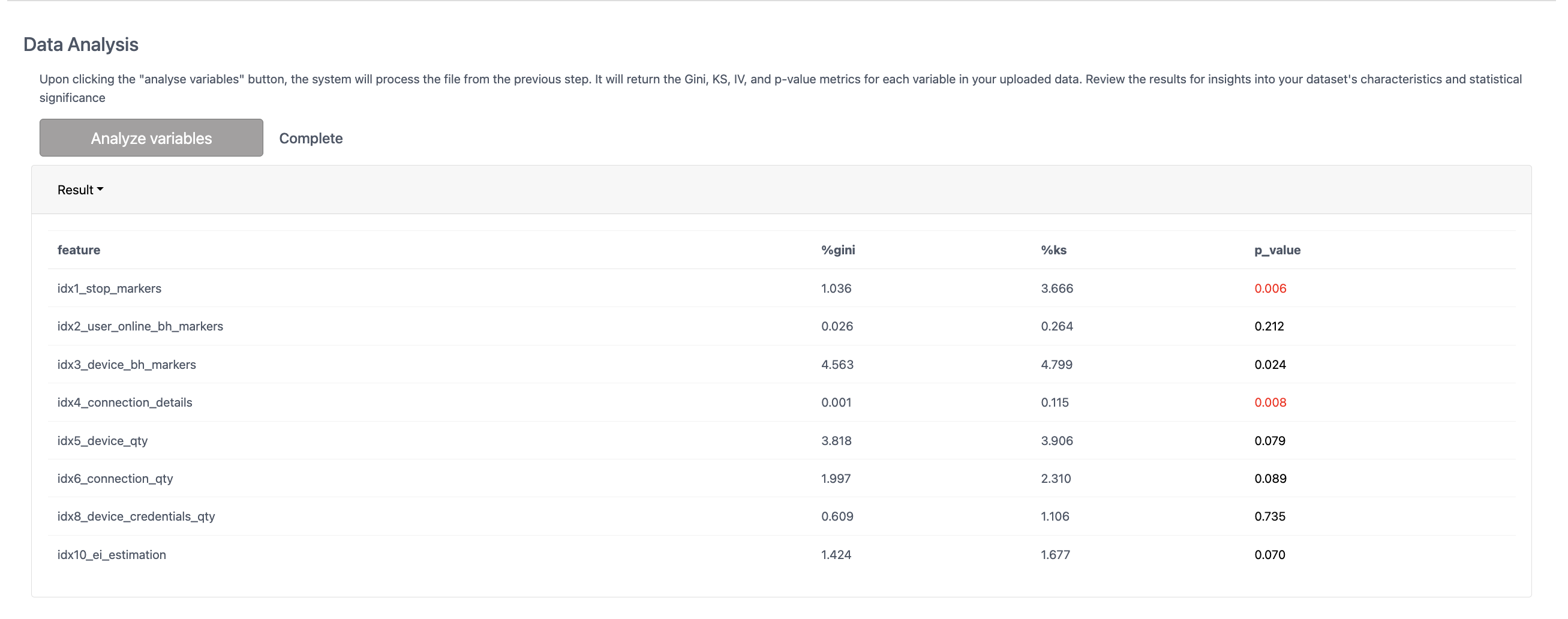
Когда эксперт загружает данные своей сессии, он видит три основные метрики для оценки информативности переменной, которую он может использовать в модели.
Статистический показатель p_value используется для расшифровки результатов тестов гипотез - если значение p_value составляет меньше 5%, данная переменная имеет статистическую значимость к целевой переменной (предсказание фроделентности сессии). По сути, значение p_value меньше 5% является рекомендацией, что данный индекс следует добавить в кастомную модель. Отдельно стоит рассмотреть критерии по приросту значения gini и значимости в смысле ks статистики.
В разделе с информацией по модели рассчитывается IV по каждому индексу. В личном кабинете можно посмотреть рекомендации, какие индексы больше всего подойдут для формирования кастомной модели.
Какие типы моделей можно построить на основании данных?
- Обобщенная линейная модель (Generalised Linear Model). В формулу можно включить различные типы данных о заемщике (не имеющих отношение к персональным данным) - количество выданных кредитов в прошлом, предполагаемую оценку располагаемого дохода. Однако в отличие от простой линейной модели, обобщенная линейная модель умеет работать и с более сложными типами данных.
- Дерево решений (Decision Tree). Использование дерева решений помогает команде максимально быстро оценить существующие риски. К основным преимуществам данной модели можно отнести его простоту и наглядность.
- Градиентный бустинг (Gradient boosting). Модель основывается на базовом прогнозе и далее учитывает все последующие этапы и итерации исправления и улучшения прогноза, таким образом, благодаря усилиям всей команды, прогноз становится наиболее точным.
После выбора типа построения модели, эксперт по рискам получает описание метрик модели. Настройка может варьироваться в зависимости от бизнес-задач. Например, если кредитору необходима более жесткая настройка и фильтры по отсечению большего числа заявок в пользу более безопасной стратегии, что, в частности, может потребоваться в период сезонного фрода, например, перед праздниками, риск-менеджер может настроить кастомную модель, которая позволяет отсекать как можно больше заемщиков с маркерами риска выше среднего по выборке.
Также эксперт может настроить модель в режиме более мягкой политики по отсечению с целью повысить процент уровня одобрения заявок. Также с помощью решения JuicyScoreAI можно настроить оптимальную модель, которая будет одновременно увеличивать уровень одобрения, а также отсеивать поток заявлений по рискам. Кроме того, каждая модель может обучаться, выбирая 60% выборки для обучения и 40% для проверки и тестирования гипотез.
Каждая функция JuicyScoreAI предназначена для оптимизации процесса от подготовки данных до развертывания модели. Понимая и используя эти функции, пользователи могут расширить свои возможности прогнозного моделирования и эффективно принимать решения на основе данных. JuicyScoreAI поддерживает ряд распространенных форматов данных и предоставляет подробную статистическую информацию для принятия решений при построении модели. Мы убеждены, что наш новый продукт будет полезен для онлайн-компаний и поможет существенно усилить их позиции в онлайн среде.