
Информация - это ценнейший ресурс в XXI веке. Ежегодно объем информации в интернете увеличивается и для обработки этих массивов данных используются различные методы. Сегодня мы остановимся на трех понятиях: искусственный интеллект (AI), машинное (ML) и глубокое обучение (DML). Существует еще огромное количество методик, которые используются специалистами и экспертами по анализу данных, и цель этой публикации не только объяснить особенности этих понятий, но и показать успешные примеры применения части методов для решения практических задач по предотвращению риска мошенничества.
Машинное обучение (ML) - это одно из специализированных направлений искусственного интеллекта, идея которого состоит в том, чтобы найти закономерность в имеющихся данных, чтобы затем ее распространить на новые объекты. Иными словами, есть некий набор или выборка значений, на которых необходимо “обучить” алгоритм, чтобы в дальнейшем применить его для решения различного вида задач, например, прогнозирования и классификации.
Глубокое обучение (DML) является подтипом машинного обучения. Основная его особенность - использование методов машинного обучения и нейронных сетей для решения реальных задач, схожих с человеческими. В DML осуществляется поиск глубоких промежуточных зависимостей между факторами. Каждый элемент найденной зависимости должен проверяться на устойчивость и может быть использован для решения задачи следующего уровня - в системе выстраивается та или иная иерархия признаков, которые были получены тем или иным статистическим алгоритмом, и каждый новый слой имеет данные о предыдущем. С практической точки зрения для решения задачи верхнего уровня применяется ансамбль моделей, каждая из которых решает одну из задач, находящихся ниже в иерархии. Например, задача по распознаванию лица человека может представлять собой совокупность нескольких задач: определение точек контура лица, определение отдельных частей лица, а также компоновка найденных элементов лица внутри ранее определенного контура лица. Среди других похожих бизнес-задач: обнаружение мошенничества/спама; распознавание речи/рукописного ввода; перевод и имитация многих иных когнитивных функций человека.
Третье понятие, которое необходимо разъяснить до прочтения основного материала - это редкие события или так называемые «аномалии». Основная особенность редкого события не только в том, что оно обладает низкой частотой возникновения, что следует из названия, а еще и тем, что возникновение такого события обычно сопровождается значительными последствиями, как позитивными, так и порой негативными. Примером такого события может быть стихийное бедствие большой разрушительной силы. Для индустрии финансов - это может быть событие, которое приводит к возникновению высокого риска списания по кредитному или убытка по договору страхования.
С одной стороны, компаниям важно уметь предсказывать появление таких событий и использовать их в своих моделях, чтобы избежать последующего риска. С другой стороны, поскольку редкие события не подчиняются нормальному закону распределения (который по определению требует значительной выборки целевых событий), моделирование таких событий серьезно осложняется.
Например, если построить обычную линейную регрессию по выборке, состоящей из 500 наблюдений, где представлено всего 5 целевых событий (то есть 1% от выборки), результатом будет уравнение, где коэффициент при независимой переменной получит первую значимую цифру только в четвертом-пятом знаке после десятичной точки, что делает такую модель абсолютно не применимой на практике.
Что же делать в этом случае?
JuicyScore, как одно из решений по оценке рисков и противодействию мошенничеству, использует алгоритмы глубокого машинного обучения при создании переменных. Примерами таких переменных могут служить индексы (или переменные типа IDX в нашем стандартном векторе данных), которые с одной стороны, извлекают полезную информативность из факторов, лежащих в основе этих индексов, а с другой стороны, позволяют нивелировать особенности сбора и недостаточность полезных значений каждого из этих факторов. Индексы позволяют использовать синергию множества таких факторов, которые могут быть использованы как отдельные переменные, отражающие аномалии одного из аспектов Интернет-соединения, для дальнейшего исследования.
За счет чего мы добиваемся высокой информативности индексов:
- Комбинируя определенным образом редкие события, каждое из которых встречается небольшое количество раз и является незначимым с точки зрения классической гауссовской статистики, нам удается добиться значимости и статистической силы комбинации таких событий;
- Переменные, входящие в индексы, обязательно имеют схожую природу и прозрачную механику формирования, что позволяет добиться, во-первых, их стабильности, а, во-вторых, позволяет снизить взаимную корреляцию различных Индексов.
Индексные переменные как пример практического применения алгоритмов машинного обучения
Разберем как мы используем методы машинного обучения на примере одной из таких переменных из нашего классического набора выходных атрибутов, а именно IDX4 - Connection details. Этот индекс описывает аномалии, связанные с интернет-соединением, попытками манипуляции с различными его особенностями и параметрами. Риск внутри этого индекса растет вместе со значением индекса.
Какова же природа этого индекса и как именно методы машинного обучения помогли выстроить зависимые факторы и подготовить данную переменную? Начнем с описания предметной области, которое схематично представлено на картинке ниже:
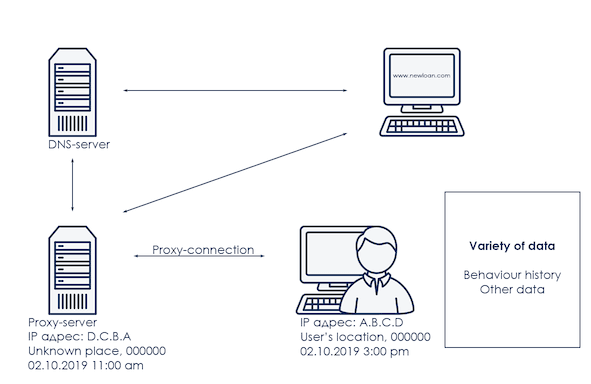
Есть устройство, с помощью которого пользователь осуществляет выход в интернет. Устройство имеет IP адрес, дату и время выхода в сеть, географические координаты и почтовый адрес, набор данных, описывающий поведение пользователя, и большое количество другой информации. Устройство обращается к некому веб-ресурсу, например сайту финансовой организации, а значит, требуется получить IP адрес этого сайта, например, найти ближайший сервер DNS. Сигнал к серверу DNS может идти не напрямую, а например, через один или несколько промежуточных, и/или проксирующих серверов. Как сервер DNS, так и проксирующие сервера, тоже имеют свои атрибуты, такие как временная зона, географические координаты и другой набор данных.
Каждый компонент предметной области, представленный на картинке, может быть детализирован и описан своим набором атрибутов, параметров и основная задача не только выявить механику возникновения и особенности, а также понять предсказательную силу и степень влияния на моделируемое событие. Например, вероятность списания по кредиту. Для более глубоко понимания мы рассмотрим несколько параметров из описываемой предметной области.
IP адрес - уникальный идентификатор узла, находящегося в сети. В данном материале мы будем иметь в виду классический IPv4 - риски и возможности IPv6 мы уже рассматривали ранее (ссылка на статью) и возможности и аномалии этого типа IP-адресов нам еще предстоит изучить.
Одной из наиболее распространенных аномалий, связанных с IP адресом, является смещение или несоответствие временной зоны устройства и временной зоны IP адреса. Почему распространенной? Потому что, во-первых, в ряде регионов нашей планеты это является обычным явлением. Во-вторых, временные зоны могут не совпадать по объективным причинам, например, при синхронизации временных зон устройства и IP адреса после перелета на самолете, этот процесс может занимать до суток. В-третьих, такое несоответствие является фактором риска.
Несоответствие временных зон может встречаться от 0.1% случаев, когда это аномалия, и до 15-20%, в тех регионах, где это может быть нормой. В любом случае, наличие данного фактора почти всегда говорит о риске, который нужно принимать во внимание и учитывать в кредитном движке в зависимости от аппетита к риску.
Еще одним часто встречающейся особенностью соединения является наличие прокси-соединения, когда по тем или иным причинам виртуальный пользователь скрывает свое местоположение или использует непрозрачную интернет инфраструктуру. Таких случаев бывает от 1% в РФ до десятков процентов в странах Юго-Восточной Азии. В тех случаях, когда таких событий немного это чаще всего говорит о намеренных действиях пользователя по скрытию своих действий от кредитора или иного финансового института - владельца веб-ресурса. В случаях, где этот показатель составляет проценты или десятки процентов, пользователь зачастую даже не знает, каким именно образом он выходит в интернет и как построено сетевое соединение. С практической точки зрения наиболее интересной является первая группа случаев, поскольку она свидетельствует о наличии небольшого или среднего риска, если это единственная аномалия, и о наличии повышенного риска, если эта аномалия усилена рядом других факторов.
Третьим примером, который в ряде случаев можно считать аномалией соединения, являются параметры сервера DNS. Этот сервис служит для разрешения привычных всех имен веб-ресурсов типа www.juicyscore.com в IP адреса. Чаще всего узел сети обращается к ближайшему расположенному к нему серверу или серверам DNS, до тех пора пока не найден сервер, который располагает информацией о том, какой IP-адрес соответствует введенному имени веб-ресурса. Но часто случается так, что ближайший сервис DNS по каким-то причинам оказывается не совсем ближайшим и может быть отделен от фактического IP адреса устройства границами государств и некоторым количеством временных зон и сотнями километров. В зависимости от страны доля таких событий также достаточно небольшая, обычно не более 3-5%, но в тех случаях, когда эта аномалия проявляется, она говорит о среднем или даже высоком уровне риска, особенно, когда сопровождается другими аномалиями.
В чем же схожи приведенные три примера:
- все они относятся к различным характеристикам интернет-соединения, то есть объединены общей механикой и единой предметной областью;
- все они представляют собой редкие события - то есть в большинстве случаев доля каждого из них в потоке заявлений на веб-ресурс финансового института ниже или значительно ниже 5%, а значит они сложны в использовании и моделировании, то есть для них неприменимы или ограниченно применимы методы классической гауссовской статистики (например, линейная или логистическая регрессия);
- все они в значительной степени влияют на риск мошенничества, поскольку зачастую связаны с принудительными и осознанными действиями пользователя устройства, а не произошли случайно.
То есть с одной стороны, исходя из своей природы, эти факторы крайне важны, а с другой стороны, сложны в использовании при автоматизации настроек и правил кредитного движка. А теперь представьте, что таких факторов не три, а пять, десять или даже несколько десятков. И каждый из них является редким событием с большой компонентой риска внутри. Что делать в этом случае?
И здесь на помощь приходят методы машинного обучения - причем как классические интерпретируемые методы (например, деревья решений) или логистическая регрессия, так и могут использоваться неинтерпретируемые методы. Мы в JuicyScore являемся сторонниками интерпретируемых методов, поскольку, во-первых, на наш взгляд, они более применимы к прогнозированию финансовых рисков, а во-вторых, являются более устойчивыми к особенностям самих данных, которые используются для моделирования.
А применяя подходы глубокого машинного обучения
- получен ряд стабильных факторов, описывающих отдельные параметры Интернет-соединения;
- каждый из этих факторов самостоятелен и может использоваться отдельно;
- совокупность факторов позволяют решать задачу более высокого уровня иерархии - определение риска мошенничества на потоке кредитных заявлений.
В итоге при использовании комбинаций озвученных выше методов получается переменная, имеющая распределение вот такого вида.
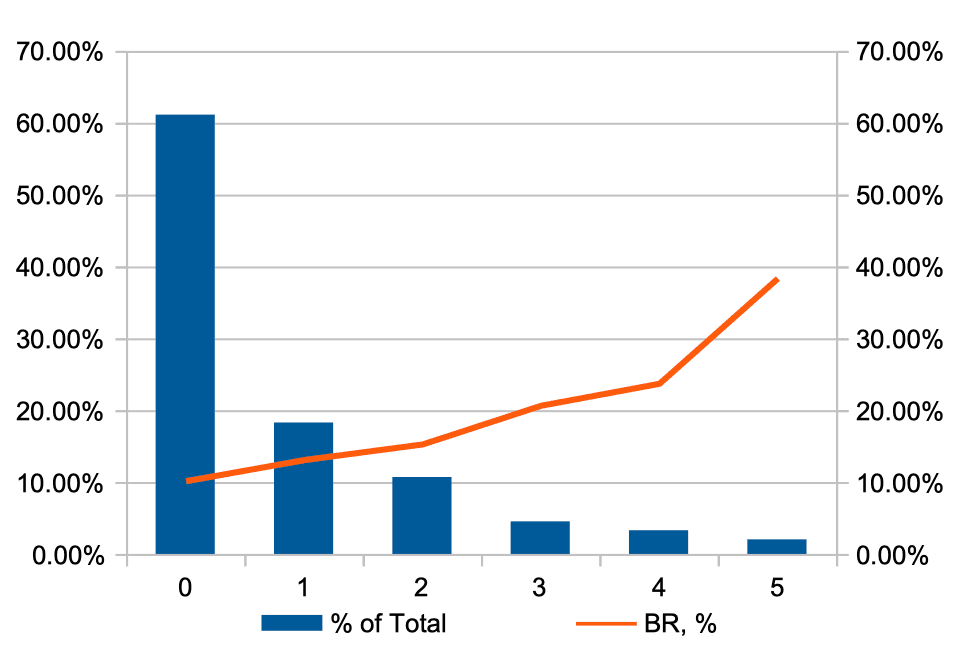
Синяя гистограмма на графике показывает распределение доли наблюдений по значениям IDX переменной, а красная ломаная линия - относительный уровень риска (BR, или bad rate) в каждой когорте.
Как видно из графика, применением методов машинного обучения удалось:
- сделать значимые когорты с точки зрения количества наблюдений в каждой и доле от общего количества;
- добиться монотонности распределения уровня целевой переменной - в данном случае уровня FPD;
- использования переменной как для моделирования риска редких событий, так и для моделирования кредитных рисков, имеющих непрерывную, а не дискретную природу.
А вот, как выглядит распределение значений индекса в зависимости от страны заявителя.
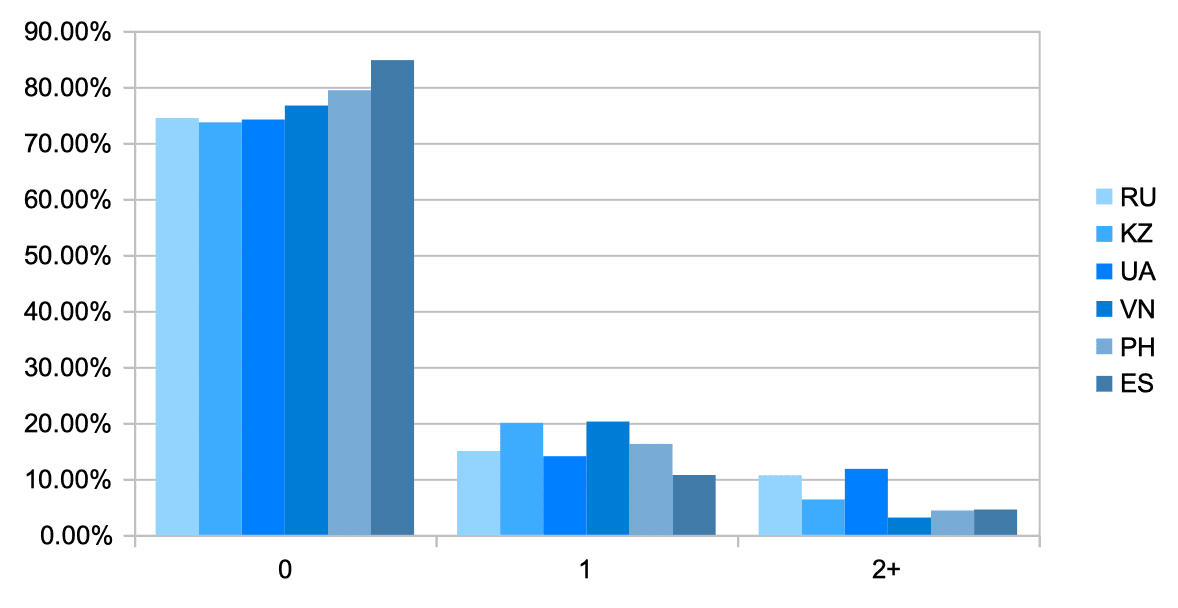
Из графика видно, что доля наблюдений, где наблюдается незначительные (когорта 1) и значительные (когорта 2+) аномалии интернет-соединения сильно зависит от региона. Неудивительно, что в том же Вьетнаме, где в силу особенностей организации интернета и нехватки IP-адресов протокола IPv4, доля этих когорт выше, чем в той же Испании, где таких событий намного меньше, и нехватка адресов формата IPv4 не ощущается в таких масштабах. Что общего у этих двух стран: наличие аномалий усложняет анализ устройства и как следствие, заявителя, а значит увеличивает вероятность риска.
Методы машинного обучения представляют собой мощный инструмент, позволяющий при понимании природы данных и правильном применении методов моделирования добиваться решения практических задач, таких как прогнозирование разного рода рисков:
- позволяют анализировать и увязывать не всегда самые очевидные зависимости;
- позволяют приводить их к форме, которая делает их пригодной для использования в различного рода моделях, работающих в кредитном движке конвейера заявок для кредитных организаций или актуарных расчетах стоимости полиса исходя из ожидаемых убытков;
- позволяют добиваться стабильности распределения во времени и интерпретируемости полученных результатов.
Поскольку любая предметная область представляет собой сложную систему, которая может быть описана бесконечным количеством факторов, параметров, метрик и атрибутов, процесс извлечения новых интересных и полезных факторов является безостановочным, а полученное на практике количество индексов - бесконечно большим, а значит, у нас есть возможность продолжать увеличивать для вас информативность нашего сервиса.