
Один из принципов работы нашей команды - это поиск полезных и информативных данных, которые помогают нашим партнерам и клиентам лучше управлять кредитными и операционными рисками. При этом критично важно не только находить атрибуты и “фичи”, позволяющие улучшить качество принятия решения, но и обеспечить прозрачность расчетов и интерпретируемость результатов. По этой причине при взаимодействии с нашими партнерами мы уделяем большое внимание механике построения атрибутов, которые входят в вектор ответа от API. Сегодня мы более подробно расскажем о некоторых маркерах поведения пользователей и принципах определения качества устройств, а также продемонстрируем, как можно существенно улучшить сегментацию входящего потока по уровню кредитного риска с помощью данных JuicyScore.
Один из основных подходов, который реализован в продукте JuicyScore, - это методология использования агрегированных переменных IDX. Они представляют собой совокупность редких событий и факторов одной природы, собранных с помощью алгоритмов Deep Machine Learning в единую переменную, которую можно использовать как для моделирования, так и для встраивания в систему принятия решений кредитных организаций. Сегодня мы более подробно разберём две индексные переменные нашего вектора данных, уделив внимание механике как самих индексных переменных, а также рассмотрим факторы, на которых они построены.
IDX2 - Маркер поведения пользователей
Эта агрегированная переменная представляет собой комбинацию различных маркеров поведения пользователя на веб-ресурсе онлайн-бизнеса. В векторе JuicyScore представлены десятки маркеров так или иначе относящихся к поведению пользователя и основная задача при дизайне данной переменной - это выявление стабильных маркеров, объединение которых в один агрегат позволяет выявлять сегменты высокого риска независимо от географии деятельности онлайн-бизнеса.
Переменная IDX2 построена на факторах, относящихся к различным категориям поведения виртуального пользователя в сети или использования устройства. С одной стороны, в нее включены факторы, относящиеся к частотным характеристикам. Например, наблюдаемое ранее количество заявлений или запросов на финансовый продукт с одного устройства или от одного виртуального пользователя с определённой периодизацией по времени или без нее, за всю историю. С другой, в состав переменной также включены параметры, определяющие стабильность или наоборот, вариативность данных, используемых в кредитном заявлении или запросе на продукт. Большое разнообразие таких данных на одном устройстве или у одного виртуального пользователя говорит о высоком операционном риске. Высокая частотность запросов без манипуляции данными в запросе или заявлении на продукт свидетельствует скорее о повышенном кредитном риске (так называемом кредитном шоппинге, когда заемщик берет несколько кредитов в разных кредитных организациях за короткий промежуток времени). Наличие одновременно высокой частности и высокой вариативности данных на одном устройстве или у одного виртуального пользователя - верный признак высокого операционного риска.
Помимо этого, переменная также включает в себя набор факторов - маркеров рискованного поведения пользователя, не относящихся к первым двум категориям. Это маркеры способов заполнения заявки, способов использования устройства и так далее. По сути это комбинация редких событий среднего и высокого риска, которые при определенном способе объединения можно использовать в системе принятия решений и моделях, построенных при помощи классических гауссовских методов.
В результате всех этих действий мы получаем переменную, имеющую целочисленые значения от 1 до 6, которая позволяет сегментировать поток по уровню риска и имеет стабильные зоны, которые можно использовать в моделях или в стоп-фильтрах. Например, диапазоны 1-2 - это зона низкого риска, которая зачастую лучше по качеству, чем популяция или выборка в целом. Далее в рамках этого сегмента можно искать дополнительные сегменты для одобрения. Диапазоны 5-6 - это зоны высокого риска, обычно небольшие по размеру, которые можно использовать в качество фильтров или правил на отказ. Ниже представлен примерный обобщенный график изменения уровня риска по диапазонам переменной.
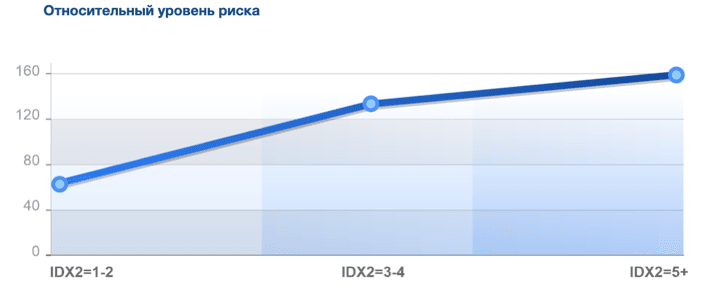
Как мы видим из графика, показатель переменной 1-2 говорит о низком риске, 3-4 - средний риск, при котором рекомендована дополнительная проверка/валидация, значение индекса больше 5 говорит о высоком риске и рекомендации к отказу.
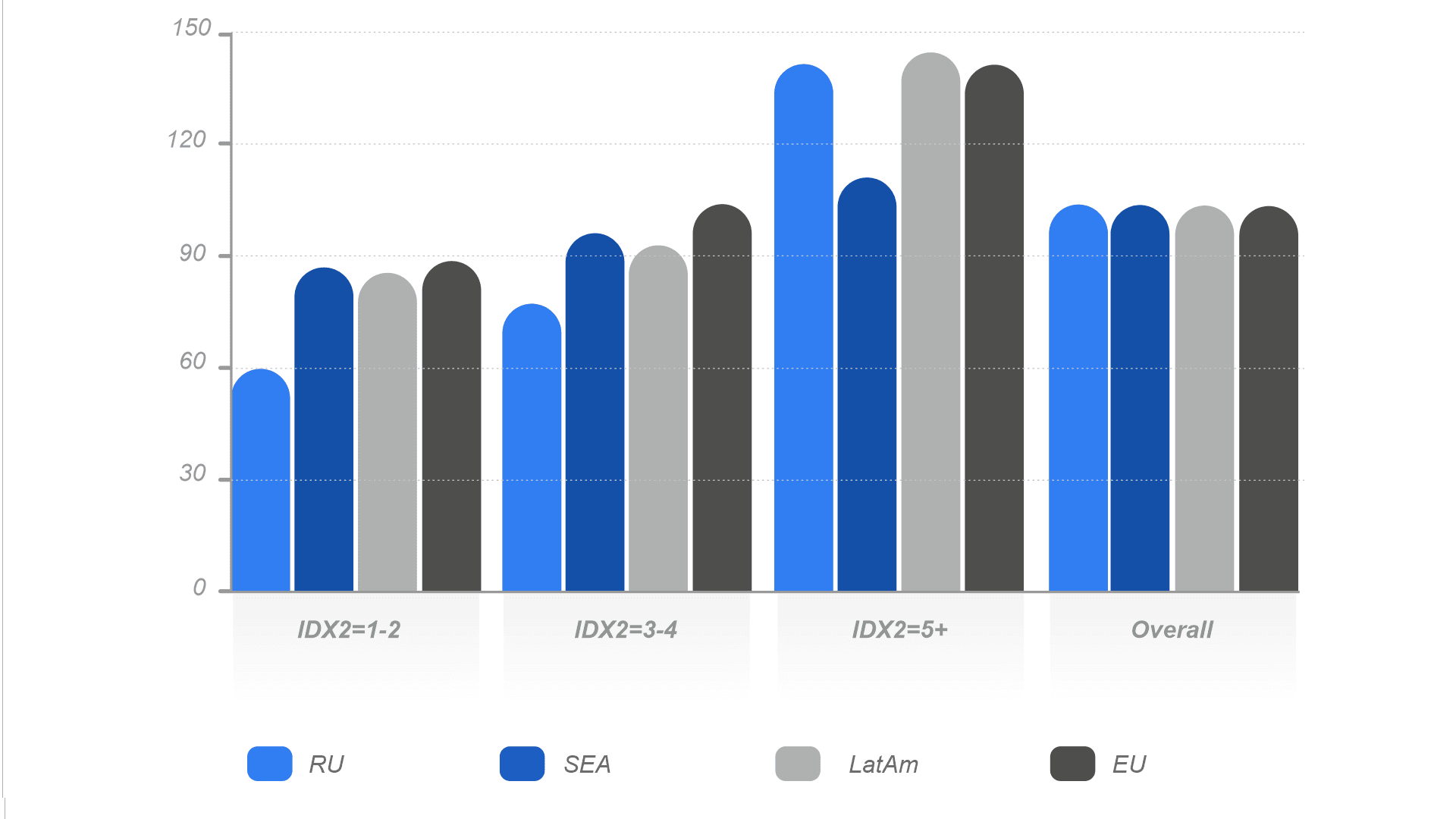
Распределение значений IDX2 по регионам
IDX5 - Индекс качества устройства
При определении и операционного риска основная задача - это отказать заявителям с высоким риском невозврата и неплатежей по обязательствам. В то время как основная задача определения кредитного риска - найти сегменты, которым можно предоставить финансовый продукт с правильными параметрами. Агрегированная переменная IDX5 относится ко второй категории, с ее помощью можно сегментировать входящий поток по уровню кредитного риска. Это имеет особенно важное значение, когда на рынке не хватает традиционных данных по кредитным историям, либо данные низкого или среднего качества.
Какой подход используется для построения данной переменной?
Функцией качества устройства является уровень его стоимости, на которые могут влиять следующие категории данных: тип устройства (например, десктоп или мобильное устройство), совокупность метрик его технических характеристик (например, объем памяти, количество ядер, качество памяти и другие) и производитель (устройство известного бренда или редко встречающая модель). Важная особенность: устройства с определенными аномалиями по техническим характеристикам не включаются в данный индекс для достижения большего уровня ортогональности с другими агрегированными переменными IDX.
У каждого устройства есть большое количество технических метрик и параметров, которые влияют на его качество и могут быть использованы в том числе для оценки кредитного риска. Поэтому важнейшей задачей при построении данного Индекса было выявить такие метрики и правильно смоделировать факторы на их основе, чтобы обеспечить стабильность распределения значений каждого фактора, при этом обеспечив стабильность распределения значения самого Индекса качества устройства и усилив его разделяющую способность. Говоря о стабильности распределения значений Индекса, ее важно обеспечить как во времени, так и по всем географиям, где ведут операционную деятельность наши партнеры и клиенты.
С точки зрения интерпретации значений Индекса качества устройства, часть потока с низкими значениями данного Индекса выявляет сегмент с высоким кредитным риском и низким уровнем располагаемого дохода. Часть потока с высокими значениями данного Индекса позволяет выделить сегменты с низким уровнем кредитного риска.
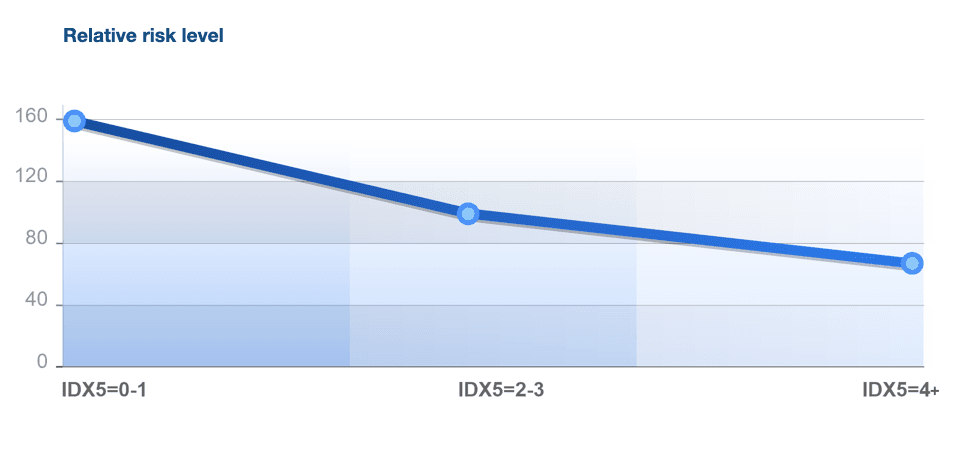
Как мы видим из графика, значения переменной 0-1 говорят о высоком кредитном риске, при котором рекомендована дополнительная проверка/валидация, а возможно и отказ. Значение индекса более 4 говорит о низком кредитном риске, в этом сегменте можно искать дополнительные выдачи.
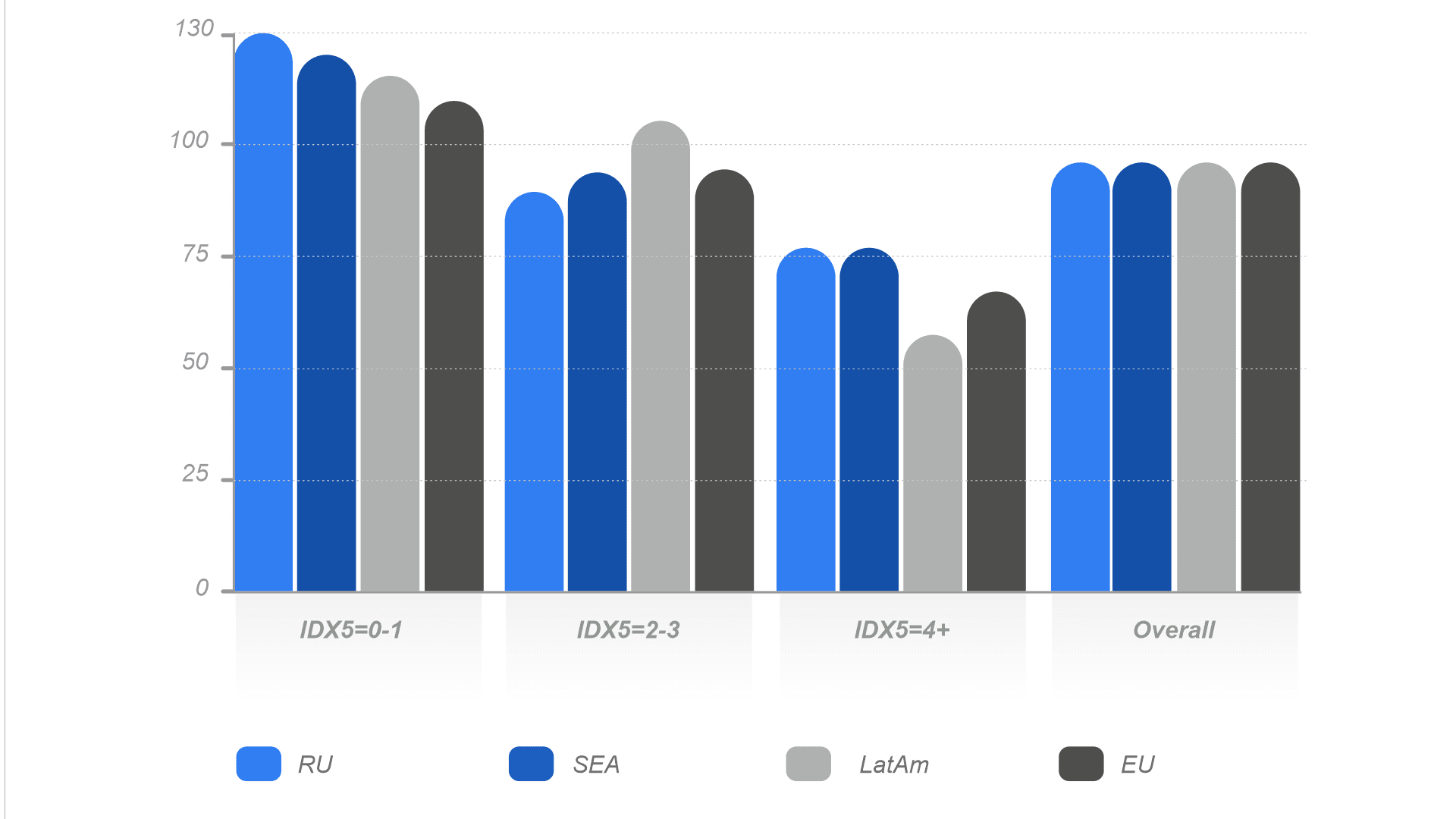
Распределение значений IDX5 по регионам
Данный параметр особенно полезен в большом количестве географий, особенно странах Юго-Восточной Азии и Африки, где есть проблема с достоверными и регулируемыми источниками данных.
Безусловным преимуществом использования индексных переменных является их универсальность - их можно включить в набор правил, фильтров, а также использовать отдельно как компонент модели по определению операционного или кредитного риска, для выявления наиболее опасных сегментов или, наоборот, позитивных сегментов. В сущности каждый Индекс сам по себе является самостоятельной моделью. Рассматриваемые маркеры и переменные являются лишь небольшой частью того расширения информативности, которое мы предлагаем в рамках нашего API.
JuicyTeam понимает, насколько важно постоянно работать над расширением набора маркеров и стоп-факторов, которые помогают сократить расходы и значительно уменьшить потери от риска мошенничества, а также предоставляет клиентам и партнерам лучший набор инструментов, позволяющий противостоять недобросовестным практикам и мошенничеством заявкам.
Другие статьи по теме. Мы более подробно освещали вопрос о нашем подходе к построению переменных в статье "Deep Machine Learning - Докопаться до истины", где рассматривали способ построения индексной переменной по сетевым аномалиям. Также ранее мы писали о переменных IDX1 - Комбинация стоп-факторов и IDX3 - Комбинация аномалий устройства в материале о ценности анализа устройств, которые построены по похожему механизму, но нацелены на несколько иную предметную область.